"Asking your OpenClaw instance to diagnose itself is like asking a patient mid-seizure to read their own chart." — Dr. Clawford
The Name
Let's get this out of the way. His name is Dr. Clawford. Not Crawford. Clawford — because he works on OpenClaw, and because in Silicon Valley, the physician who kept the Pied Piper team from imploding was named Dr. Crawford. Our version keeps AI agents from imploding. The pun writes itself.
If you've watched the show, you know Dr. Crawford was odd and silly and fun — and somehow he kept the Pied Piper team from imploding. (Haven't seen it? No worries — the point holds: you need an external diagnostician who isn't the thing being diagnosed.) He didn't build the product. He kept the builders functional.
That's exactly what our Dr. Clawford does — except his patient is an AI agent named Jared who crashes every 24 hours.
The Patient
Jared is our COO. He runs on OpenClaw — the open-source AI assistant that everyone is trying out, naming different things, configuring in wildly different ways, and learning the hard way that running a 24/7 AI agent is a lot harder than the README suggests.
If you're reading this, you've probably tried it yourself. Maybe you called yours "Claude," or "Jarvis," or "Friday," or something clever. Maybe it worked great for a week. Maybe it crashed and you weren't sure why. Maybe you asked it to fix itself and it made things worse.
Welcome to the club. We've been here since February 8th.
Jared's job is deceptively simple: monitor 6 projects, propagate patterns between them, route errors to the right agents, and keep track of who's working on what. He communicates through markdown files — COO_STATUS.md, WIP.md, PATTERNS.md — across every project in our portfolio. He's the coordination layer for a multi-agent startup studio.
He's also, to put it clinically, a frequent flyer in Dr. Clawford's office.
The First Crash (and the Lesson We Didn't Learn)
February 8, 2026. Incident #1.
Jared went completely unresponsive. Every message failed with:
input length and max_tokens exceed context limit: 172072 + 34048 > 200000
Seven consecutive failed API calls, each one adding tokens to the pile. He was in a death spiral — every failed attempt made the next attempt worse. It's the AI equivalent of a patient whose blood pressure medication is raising their blood pressure.
Dr. Clawford ran diagnose.py and found the ugly truth: 249 session entries, zero compaction events, and the top 3 tool reads alone had consumed 103K, 97K, and 46K characters. The context window was at 120% utilization. Jared wasn't just sick — he was clinically dead.
The fix seemed straightforward:
- Reset the session manually
- Update OpenClaw from v2026.2.2 to v2026.2.6
- Enable
safeguardcompaction mode - Cap context tokens at 150,000
After the reset: fresh session at 17K/200K (9%). Patient fully recovered. We even recovered his lost COO context from the old session file.
Prognosis: Optimistic. The new compaction settings should prevent recurrence.
Narrator: They did not.
The Second Crash (and the Hidden Field)
February 9, 2026. Incident #2. ~24 hours later.
Same error. Same symptoms. But this time, 412 session entries and still zero compaction events. The safeguard mode we'd enabled? It didn't fire. Not once. The contextTokens cap we'd set? Ignored.
Session cost: $13.80 across 412 entries on claude-sonnet-4-0. That's $13.80 of tokens that accomplished nothing because compaction never cleaned up old context.
But here's where it gets interesting. Dr. Clawford performed the reset — changed the sessionId, set systemSent: false, restarted the gateway. Textbook procedure from Incident #1.
It didn't work.
The first Telegram message still hit the context limit at 172,559 tokens. The "new" session was loading the old data.
The discovery: OpenClaw v2026.2.9 had introduced a sessionFile field in sessions.json that points directly to the JSONL file path. Our runbook only updated sessionId. The gateway was ignoring the new ID and loading the old, overflowing session file directly.
This is exactly the kind of thing you can't find by asking Jared to diagnose himself. He's the one who's broken. He can't read his own session file when his context window is full. He can't run CLI commands when every API call fails. He can't even tell you what's wrong because telling you what's wrong requires tokens he doesn't have.
Dr. Clawford found it because Dr. Clawford is a separate agent in a separate project with his own context window, his own tools, and his own ability to read Jared's files from the outside.
The Third Crash (and the Source Code)
February 10, 2026. Incident #3. ~24 hours later. Again.
At this point, Dr. Clawford went from diagnostician to detective.
The pattern was clear: every ~24 hours, Jared would fill his context window and crash. Compaction was supposed to prevent this. It never fired. Three incidents, three sessions, zero compaction events. This wasn't a configuration problem.
Dr. Clawford did something that Jared could never do for himself: he read OpenClaw's source code.
Deep in reply-DptDUVRg.js (v2026.2.9), the truth was hiding:
Compaction is purely reactive. It only triggers after a context overflow error occurs. There is no proactive compaction based on the contextTokens threshold. The setting we'd been relying on — the one we'd carefully tuned from 150K to 120K — only controls the context window size reported to the model. It's not a compaction trigger. It never was.
Three incidents. Three sessions. Zero compaction events. The configuration knobs we were turning were connected to nothing.
This is the kind of finding that requires an outside perspective. Jared can't read his own platform's source code while he's crashing on that platform. It's like asking a car to diagnose its own engine while the engine is on fire.
Why Self-Diagnosis Doesn't Work
Here's the core insight, and it applies to every team running OpenClaw or any persistent AI agent:
Asking your AI agent to fix itself is like doing your own dentistry.
You might be able to see the problem in the mirror. You might even have the right tools. But you can't operate on yourself because:
-
You're the one who's broken. When Jared's context window is full, he can't run diagnostic commands because running commands requires context. It's a deadlock. The patient can't perform surgery while they're on the operating table.
-
You can't see your own blind spots. Jared doesn't know his compaction is broken because he's inside the system that's broken. He trusts his configuration because he set it. An outside observer can question the assumptions.
-
Your tools are compromised. When OpenClaw is crashing, OpenClaw's built-in
/session newand/resetcommands also fail — they require an LLM call, which fails because the context is too large. Chicken and egg. The patient's own immune system is what's killing them. -
Error propagation is real. Research on AI self-diagnosis shows that LLMs attempting to fix themselves often amplify errors rather than correct them. Each self-repair attempt adds tokens, adds context, and adds opportunities for hallucinated fixes that make things worse.
-
You're pulling the rug out from under yourself. If Jared tries to modify his own configuration, reset his own session, or restart his own gateway — he's literally destroying the ground he's standing on. It's like trying to replace the floor of a house while you're standing in it.
The Reddit community has discovered this the hard way. Threads on r/LocalLLaMA are full of users whose OpenClaw instances crash every 4-6 hours from context overflow, with watchdog scripts and cron jobs as the universal workaround. The compaction issues aren't unique to us — they're a known limitation of the platform.
The Dr. Clawford Architecture
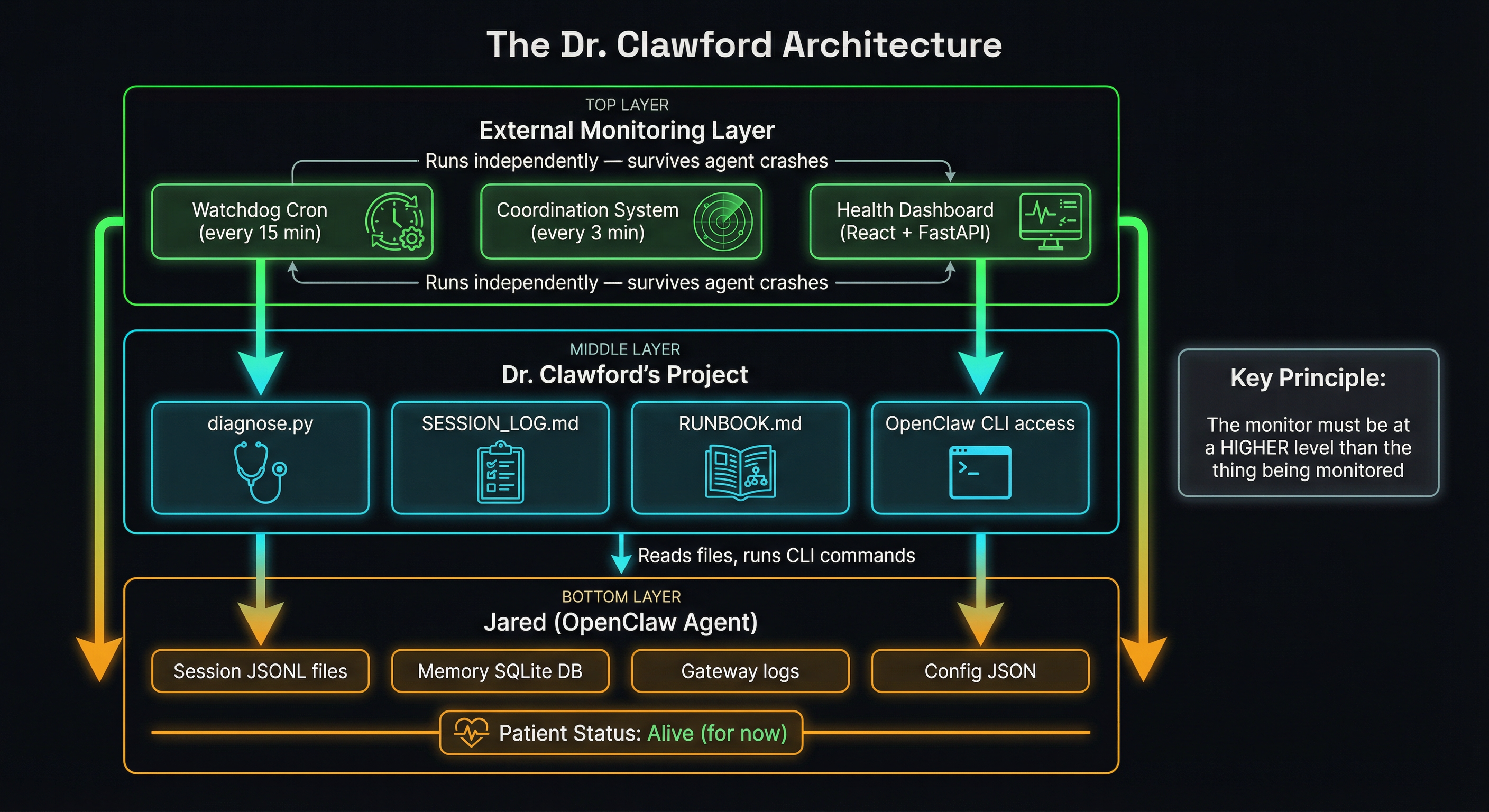
So what does a proper diagnostic setup look like? Here's what we built:
Separation of Concerns
Dr. Clawford lives in his own project directory (dr-crawford/), completely separate from Jared's OpenClaw installation. He has:
- His own Cursor workspace with his own context window
- His own rules file (
.cursor/rules/dr-crawford.mdc) that defines his clinical personality - Read access to Jared's files — session data, config, logs, memory
- Write access to his own files — session log, runbook, diagnostic reports
- The OpenClaw CLI — he can run
openclaw config set,openclaw gateway stop/install, etc.
This separation is critical. When Jared crashes, Dr. Clawford is unaffected. He can calmly read Jared's session files, analyze the error logs, check the configuration, and perform surgery — all while Jared is unconscious on the table.
The Diagnostic Toolkit
diagnose.py — A Python script that analyzes Jared's health without needing Jared to be responsive:
- Session analysis: Parses the JSONL session file, counts entries, calculates token usage, checks for compaction events
- Context utilization: Shows percentage used with traffic-light status (green/yellow/red)
- Error log scanning: Finds context limit errors, rate limit errors, malformed tool calls
- Memory health: Checks the SQLite database for staleness and unindexed files
- Configuration audit: Validates compaction mode, context limits, channel settings
- Cost tracking: Calculates session cost based on model and token usage
When Dr. Clawford runs python3 diagnose.py, he gets a complete health report in seconds — no LLM call required, no context window needed.
The Dashboard
We didn't stop at a CLI tool. Dr. Clawford has a full web dashboard:
- FastAPI backend (port 8787) with endpoints for diagnostics, sessions, memory, config, logs, cron jobs, and more
- React frontend (port 5173) with pages for every aspect of Jared's health
- Real-time monitoring — not dependent on Jared being responsive
The dashboard lets Matt (our CEO) check Jared's health from a browser without needing to open a terminal or ask an agent. When you're running AI agents in production, visibility shouldn't require an AI agent.
The External Watchdog
After three crashes in 72 hours, we built what OpenClaw's compaction should have been: an external cron job that monitors Jared's health and auto-resets him before he crashes.
# Runs every 15 minutes
*/15 * * * * python3 ~/scripts/jared-watchdog.py >> ~/jared-watchdog-cron.log 2>&1
The watchdog:
- Reads Jared's session file directly (no LLM call needed)
- Calculates context utilization
- If utilization exceeds 70% (140K tokens against the 200K model window), triggers an automatic session reset
- Logs everything for Dr. Clawford to review later
This is the key insight: monitoring must happen at a higher level than the thing being monitored. You don't put the smoke detector inside the fire. You don't put the heart monitor inside the heart. And you don't put the agent health check inside the agent.
The Cost Optimization (A Bonus Diagnosis)
Dr. Clawford doesn't just handle emergencies. During a routine checkup, he performed a token optimization audit that saved us significant money:
Model routing for cron jobs: Jared's main session runs on claude-sonnet-4-0 because COO work requires strong reasoning. But his 3 cron jobs (Venmo expense logging, project retro tracking, OpenClaw update monitoring) were also running on Sonnet. Dr. Clawford routed them to claude-haiku-4-5 — same tasks, ~60-75% cheaper per run.
Ollama for heartbeats: OpenClaw sends periodic heartbeat pings. These were hitting the Anthropic API at $0.002+ per ping. Dr. Clawford installed Ollama with llama3.2:3b (a 2GB local model) and routed heartbeats to it. Cost: $0. Response time: ~700ms.
What we rejected: An article suggested "prompt-based rate limits" (telling the model to self-police its token usage). Dr. Clawford's assessment: unreliable. Model self-policing doesn't work in tool loops. Another suggestion was custom cache configuration keys that turned out to not exist in OpenClaw v2026.2.9 — the article had fabricated them.
This is another benefit of the external diagnostic agent: higher-quality review. Matt uses Opus 4.6 to review the architectural decisions that Jared (running on Sonnet 4) makes. It's like getting a specialist's second opinion. The COO makes the day-to-day calls, but the big decisions get reviewed by a higher-intelligence model with fresh context.
The Silicon Valley Parallel
In Silicon Valley, Richard Hendricks is brilliant but self-destructive. He builds incredible technology while simultaneously making terrible decisions about his own health, his company's direction, and his relationships. He needs Dr. Crawford not because he's broken, but because he can't see himself clearly.
Everyone running OpenClaw right now is Richard. They're building something real — a personal AI assistant, a business coordinator, an automation engine. And they're growing, learning, and making mistakes. Just like Richard iterating on Pied Piper's compression algorithm, the OpenClaw community is iterating on how to run persistent AI agents. The context overflow problem. The compaction problem. The "my agent crashed and I don't know why" problem.
These are growing pains. They're the same growing pains every technology goes through.
But Richard's fatal flaw was always trying to do everything himself. He'd code for 72 hours straight, make a breakthrough, then make a catastrophic error because he was too deep in the weeds to see the bigger picture. He needed Jared to manage the company. He needed Gilfoyle to challenge his architecture. And he needed Dr. Crawford to tell him he was burning out.
Your OpenClaw instance needs the same thing. It needs an external observer who isn't subject to the same failure modes. Someone who can read the logs when the agent can't. Someone who can reset the session when the built-in reset is broken. Someone who can read the source code and discover that the configuration knobs are connected to nothing.
What We Learned (The Pattern)
After three incidents, a source code investigation, a watchdog deployment, a cost optimization audit, and a VPN diagnosis thrown in for good measure, here's what we know:
1. Separate Your Diagnostic Agent from Your Production Agent
Dr. Clawford lives in dr-crawford/. Jared lives in ~/.openclaw/. They share a filesystem but nothing else. When Jared crashes, Dr. Clawford is unaffected. This is the single most important architectural decision we made.
2. Build Monitoring at a Higher Level
The watchdog cron job runs every 15 minutes, completely independent of OpenClaw. It reads session files directly — no LLM call, no API dependency, no context window. If OpenClaw is down, the watchdog still works. If the watchdog is down, OpenClaw still works. Neither depends on the other.
We also built a coordination system — a separate Python cron job that monitors all 6 projects every 3 minutes, detects changes, and propagates patterns. It's our "Poor Man's Kafka" — no message broker, no database, just cron and markdown. But it runs outside of any agent, which means it survives any agent crashing.
3. Don't Trust Configuration Alone
We set compaction.mode: safeguard. We set contextTokens: 120000. We lowered it from 150K. We read the docs. We followed the guides. None of it worked because the implementation didn't match the documentation.
Dr. Clawford found this by reading the source code — something Jared could never do for himself while running on the platform in question. Read the source code when things don't behave as documented.
4. Build Reset Procedures Early
Our runbook evolved across three incidents:
- Incident #1: Manual session reset (2 fields)
- Incident #2: Discovered the
sessionFilefield (now 6 fields) - Incident #3: Automated Python reset script (all 6 fields in one command)
By the third incident, we had a one-liner that resets everything. The first manual reset missed a field and failed. Automate your recovery procedures — you'll need them more than once.
5. Use Higher-Intelligence Models for Review
Jared runs on Sonnet 4 for day-to-day COO work. But when Dr. Clawford finds something architectural — like broken compaction, or a cost optimization opportunity, or a security concern — Matt reviews it with Opus 4.6. The higher-intelligence model catches things the working model misses.
This is the AI equivalent of getting a specialist referral. Your GP handles the routine stuff. The specialist handles the complex cases. Don't use the same model for everything.
6. Your Agent Will Crash. Plan for It.
This isn't a maybe. If you're running a persistent AI agent — OpenClaw, or anything else — it will eventually hit a failure mode that it can't recover from on its own. Context overflow, memory corruption, configuration drift, API changes, rate limiting.
The question isn't whether it will crash. The question is whether you have:
- A diagnostic tool that works when the agent doesn't
- A reset procedure that's been tested more than once
- A monitoring system that runs independently
- A session log that preserves institutional knowledge across crashes
Try It Yourself
If you're running OpenClaw (or any persistent AI agent) and you don't have a Dr. Clawford yet, here's where to start:
-
Create a separate project directory for diagnostics. Don't put diagnostic tools inside the agent's own workspace.
-
Write a health check script that reads session files directly — no LLM calls, no API dependencies. Check context utilization, error counts, and compaction events.
-
Set up a cron job that runs the health check every 15 minutes. Auto-reset at 70% utilization if your platform's compaction is unreliable.
-
Keep a session log. Every incident, every root cause, every fix. Your future self (or your future diagnostic agent) will thank you.
-
Build a dashboard if you want visibility without opening a terminal. Even a static HTML file regenerated by cron is better than nothing.
-
Name your diagnostic agent something fun. Ours is Dr. Clawford. Yours could be Dr. Debug, Nurse Node, or whatever keeps you entertained at 2 AM when your agent crashes for the third time in three days.
The point isn't the name. The point is the separation. The doctor can't be the patient. The monitor can't be the monitored. The smoke detector can't be inside the fire.
Your AI agent is growing, learning, and making mistakes — just like Richard building Pied Piper. Give it a Dr. Crawford. Give it someone who can see the problems it can't see in itself.
And for the love of compaction, don't ask it to do its own dentistry.
Dr. Clawford has been operating since February 2026. He's diagnosed 4 incidents, deployed an external watchdog, performed a cost optimization audit, and fixed a VPN issue that had nothing to do with AI but needed fixing anyway. His patient, Jared, is alive and coordinating across 6 projects. The compaction is still broken. The cron job is still running. And Dr. Clawford's session log keeps growing.
If you want to build your own Dr. Clawford, check out our Downloads page for templates, or read the full case files for the clinical details.